
363·
30 days agoYeah, the glaring problem of having to share your phone number is gone too:
https://support.signal.org/hc/en-us/articles/6712070553754-Phone-Number-Privacy-and-Usernames
#nobridge
Yeah, the glaring problem of having to share your phone number is gone too:
https://support.signal.org/hc/en-us/articles/6712070553754-Phone-Number-Privacy-and-Usernames
OpenAI does not make hardware.
Yeah, I didn’t mean to imply that either. I meant to write OneAPI. :D
It’s just that I’m afraid Nvidia get the same point as raspberry pies where even if there’s better hardware out there people still buy raspberry pies due to available software and hardware accessories. Which loops back to new software and hardware being aimed at raspberry pies due to the larger market share. And then it loops.
Now if someone gets a CUDA competitor going that runs equally well on Nvidia, AMD and Intel GPUs and becomes efficient and fast enough to break that kind of self-strengthening loop before it’s too late then I don’t care if it’s AMDs ROCm or Intels OneAPI. I just hope it happens before it’s too late.
That do sound difficult to navigate.
With OpenAPI OneAPI being backed by so many big names, do you think they will be able to upset CUDA in the future or has Nvidia just become too entrenched?
Would a B580 24GB and B770 32GB be able to change that last sentence regarding GPU hardware worth buying?
I don’t have any personal experience with selfhosted LMMs, but I thought that ipex-llm was supposed to be a backend for llama.cpp?
https://yuwentestdocs.readthedocs.io/en/latest/doc/LLM/Quickstart/llama_cpp_quickstart.html
Do you have time to elaborate on your experience?
I see your point, they seem to be investing in every and all areas related to AI at the moment.
Personally I hope we get a third player in the dgpu segment in the form of Intel ARC and that they successfully breaks the Nvidia CUDA hegemony with their OneAPI:
https://uxlfoundation.org/
https://oneapi-spec.uxlfoundation.org/specifications/oneapi/latest/introduction
All GDDR6 modules, be they from Samsung, Micron, or SK Hynix, have a data bus that’s 32 bits wide. However, the bus can be used in a 16-bit mode—the entire contents of the RAM are still accessible, just with less peak bandwidth for data transfers. Since the memory controllers in the Arc B580 are 32 bits wide, two GDDR6 modules can be wired to each controller, aka clamshell mode.
With six controllers in total, Intel’s largest Battlemage GPU (to date, at least) has an aggregated memory bus of 192 bits and normally comes with 12 GB of GDDR6. Wired in clamshell mode, the total VRAM now becomes 24 GB.
We may never see a 24 GB Arc B580 in the wild, as Intel may just keep them for AI/data centre partners like HP and Lenovo, but you never know.
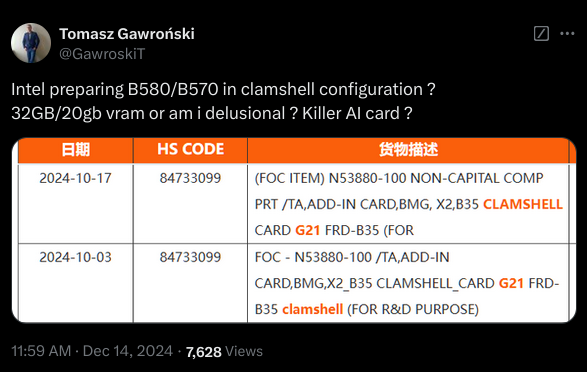
Well, it would be a cool card if it’s actually released. Could also be a way for Intel to “break into the GPU segment” combined with their AI tools:
They’re starting to release tools to use Intel ARC for AI tasks, such as AI Playground and IPEX LLM:
https://game.intel.com/us/stories/introducing-ai-playground/
https://www.intel.com/content/www/us/en/products/docs/discrete-gpus/arc/software/ai-playground.htmlhttps://game.intel.com/us/stories/wield-the-power-of-llms-on-intel-arc-gpus/
https://github.com/intel-analytics/ipex-llm
That they do, but your contacts doesn’t have to get it anymore.
A self-hosted matrix stack built from source with matrix clients built from source with e2ee implemented that you yourself have the competence to verify the encryption and safety of would be the only secure communication I know of if you don’t want to trust a third party.